Science des données et recherche scientifique
Nouvelles données et nouveaux modèles
3.3 Combinaison des données structurées et non-structurées
Frackmap est un exemple de combinaison de données structurées et non-structurées.
Objectif: comprendre l’impact des puits de gaz de schiste sur les communautés locales
- Données structurées: données sur les puits de gaz de schiste
- Données non-structurées: données sur les tweets
- Données non-structurées: textes scientifiques de santé publique

4.1 Exemples
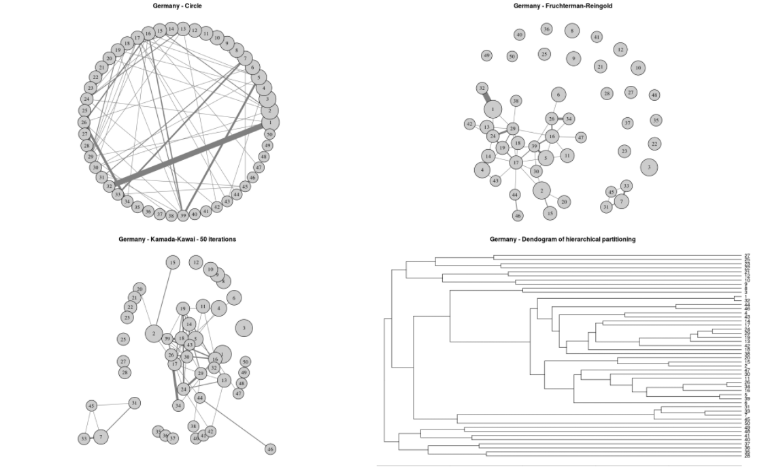
Objectif : Identifier les relations entre les acteurs d’un réseau social.
Méthodes : Analyse des réseaux sociaux, détection de communautés, etc.
Applications : 43 499 directeurs de CA de banques
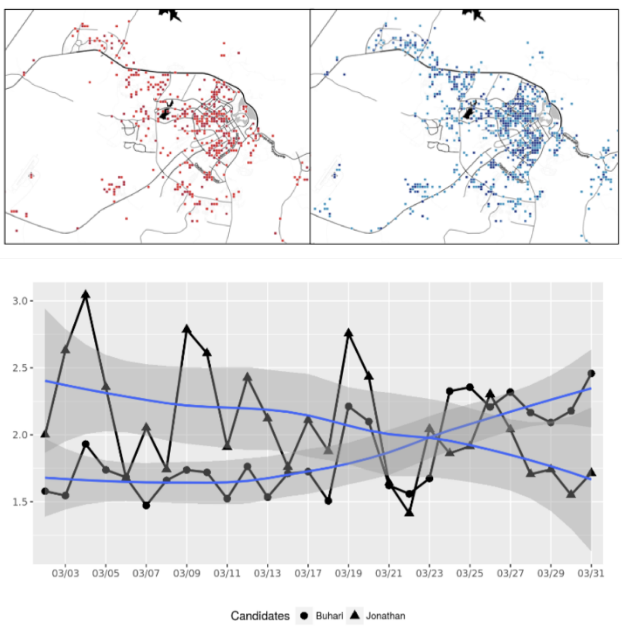
Objectif : Analyser des textes et des langages humains.
Méthodes : Analyse de sentiments, classification de textes, résumé automatique, etc.
Applications : 3.8 millions de tweets sur les élections présidentielles nigériennes.
Objectif : Analyser des images et des vidéos.
Méthodes : Reconnaissance d’images, détection d’objets, etc.
Applications : Haïti
Objectif : Analyser des données temporelles.
Méthodes : Modèles ARIMA, modèles LSTM, etc.
Applications : Prévisions économiques, etc.
10.1 Restons connectés
- Mon LinkedIn: linkedin.com/in/thierrywarin

![]()