Contenu
Plan
Dans la partie 1, nommée Contexte, vous découvrirez le contexte de l'exercice. Dans la section 2, Productivité des auteurs, vous allez aggréger des données puis les visualiser à l'aide d'un graphique en barre. Dans la partie 3, Productivité des pays, vous apprendrez à créer une carte. Enfin, les parties 4 et 5, Collaboration des auteurs et Collaboration des pays respectivement, vous montrerons des exemples d'analyse de réseaux.
Instructions
L'exercice est divisé en plusieurs parties offrant différents modes d'interaction. Les interactions vous fournissent des informations supplémentaires, testent vos connaissances ou vous demandent d'écrire vos propres bouts de code. Vous n'êtes pas tenus de résoudre les exercices dans l'ordre donné, mais comme ils se complètent, il est recommandé de les faire dans l'ordre. Vous trouverez ci-dessous les différents types d'interactions avec leur fonction correspondante :
Les boîtes d'information fournissent des informations supplémentaires.
Les boites de code vous obligent à interagir avec les morceaux de code et sont marqués comme Tâche. Le processus de résolution des boites de code est assez intuitif :
startover: Nettoie votre boite de code pour ne garder que le code préétabli.solution: Affiche la solution de la tâche.run code: Exécute le code sans vérifier son exactitude.submit answer: Semblable à run code, vous exécutez le chunk mais cette fois, l'exactitude de votre réponse est vérifiée.
Contexte
En ces temps incertains, vous êtes engagé par l' Organisation mondiale de la santé (OMS) afin de récolter des informations à propos de la Covid-19. En tant qu'analyste, vous décidez de vous pencher sur les données bibliographiques puisque des centaines d'articles ont été écrits à ce sujet depuis le début de la pandémie.
Productivité des auteurs
Vous souhaitez maintenant également savoir quels auteurs publient le plus au sujet de la Covid-19.
Tâche 1 : Téléchargeons à nouveau les données dans une variable appelée mydata en effectuant la ligne de code ci-dessous.
mydata <- mydata <- EpiBib_dataTâche 2 : Ensuite, il faut aggréger les données par auteur. Additionnez le nombre de lignes en fonction de la colonne AU (auteurs) à l'aide de la fonction count() du package dplyr. Vous pouvez toujours afficher le résultat en appelant simplement mydata_AU.
mydata <-
mydata_AU <- dplyr::count(mydata, ___)mydata <- EpiBib_data
mydata_AU <- dplyr::count(mydata, AU)Tâche 3 : Maintenant, vous voulez arranger les données (colonne n) en ordre décroissant avec la fonction arrange() et desc().
mydata <-
mydata_AU <- dplyr::count(mydata, ___)
mydata_AU <- dplyr::arrange(mydata_AU, desc(___))mydata <- EpiBib_data
mydata_AU <- dplyr::count(mydata, AU)
mydata_AU <- dplyr::arrange(mydata_AU, desc(n))Tâche 4 : Finalemment, il serait intéressant de visualiser ce résultat dans un graphique en barre. Les données sont fixées par ordre décroissant pour les afficher ainsi dans le graphique (reorder(AU, n)). Vous affichez le Top 9 des auteurs les plus productifs. Dans ce cas, la première ligne est laissé de côté (mydata_AU[2:10,] = seules les lignes de 2 à 10 vont s'afficher), étant donné qu'il s'agit de données manquantes. Sur l'axe des abscisses vous affichez le nombre d'article (n) et sur l'axe des ordonnées les pays (AU). Vous utilisez l'option fill = pour afficher une couleur différente pour chaque pays (AU).
mydata <-
mydata_AU <- dplyr::count(mydata, ___)
mydata_AU <- dplyr::arrange(mydata_AU, desc(___))
ggplot(data = mydata_AU[2:10,], aes(x = ___, y = reorder(AU, n), fill = ___)) +
geom_col() +
xlab("Nombre d'articles") + ylab("Pays") +
scale_fill_uchicago() +
theme_minimal() +
theme(legend.position = "none")mydata <- EpiBib_data
mydata_AU <- dplyr::count(mydata, AU)
mydata_AU <- dplyr::arrange(mydata_AU, desc(n))
ggplot(data = mydata_AU[2:10,], aes(x = n, y = reorder(AU, n), fill = AU)) +
geom_col() +
xlab("Nombre d'articles") + ylab("Auteurs") +
scale_fill_uchicago() +
theme_minimal() +
theme(legend.position = "none")Productivité des pays
Tâche 1 : Vous voulez également savoir quel pays publie le plus au sujet de la Covid-19. Pour cela, il faut en premier lieu aggréger les données par pays. La première étape est d'additionner le nombre de lignes en fonction de la colonne AU_CO (pays d'origine de l'auteur) à l'aide de la fonction count() du package dplyr. Vous pouvez ensuite arranger les données (colonne n) en ordre décroissant avec la fonction arrange() et desc(). En appelant mydata_AUCO, vous affichez le résultat généré.
mydata <-
mydata_AUCO <- dplyr::count(mydata, ___)
mydata_AUCO <- dplyr::arrange(___, desc(___))
mydata_AUCOmydata <- EpiBib_data
mydata_AUCO <- dplyr::count(mydata, AU_CO)
mydata_AUCO <- dplyr::arrange(mydata_AUCO, desc(n))
mydata_AUCOTâche 2 : Vous pouvez à présent visualiser ce résultat dans un graphique à barres. Les données sont fixées par ordre décroissant pour les afficher ainsi dans le graphique. Vous affichez le Top 9 des pays les plus productifs. Sur l'axe des abscisses vous affichez le nombre d'article (n) et sur l'axe des ordonnées les pays (AU_CO). Vous utilisez l'option fill = pour afficher une couleur différente pour chaque pays (AU_CO).
mydata <-
mydata_AUCO <- dplyr::count(mydata, ___)
mydata_AUCO <- dplyr::arrange(___, desc(___))
mydata_AUCO
ggplot(data = mydata_AUCO[1:9,], aes(x = ___, y = reorder(AU_CO, n), fill = ___)) +
geom_col() +
xlab("Nombre d'articles") + ylab("Pays") +
scale_fill_uchicago() +
theme_minimal() +
theme(legend.position = "none")mydata <- EpiBib_data
mydata_AUCO <- dplyr::count(mydata, AU_CO)
mydata_AUCO <- dplyr::arrange(mydata_AUCO, desc(n))
mydata_AUCO
ggplot(data = mydata_AUCO[1:9,], aes(x = n, y = reorder(AU_CO, n), fill = AU_CO)) +
geom_col() +
xlab("Nombre d'articles") + ylab("Auteurs") +
scale_fill_uchicago() +
theme_minimal() +
theme(legend.position = "none")Vous pouvez également afficher ces mêmes données sous formes de carte. Cela dit, un nettoyage plus approfondie des données est nécessaire. Pour construire une carte, vous pouvez appeler les données offertes par le package ggplot2 qui met à disposition toutes les longitudes et latitudes nécessaires pour tracer chaque pays. Seulement, la colonne region de world contenant le nom des pays n'est pas en majuscule comme dans notre tableau de données mydata_AUCO. Il faut donc ajuster cela en utilisant la fonction str_to_title() du package stringr. Ensuite, certains noms de pays ne sont pas écrits de la même façon dans ces deux tableaux de données. Pour les modifier, vous pouvez utiliser la fonction gsub(). À titre d'exemple, nous adaptons 3 noms du tableau de données mydata_AUCO à ceux des données de la carte world. Il est nécessaire de passer par cette étape pour pouvoir assembler les données de ces deux tableaux ensemble. Une fois les deux tableaux assemblés grâce à la fonction left_join(), il est possible de réaliser le graphique.
Tâche 3 : Roulez le code.
mydata <- EpiBib_data
mydata_AUCO <- dplyr::count(mydata, AU_CO)
mydata_AUCO <- dplyr::arrange(mydata_AUCO, desc(n))
world <- ggplot2::map_data("world")
mydata_AUCO$AU_CO <- stringr::str_to_title(mydata_AUCO$AU_CO)
mydata_AUCO$AU_CO <- gsub("United States", "USA", mydata_AUCO$AU_CO)
mydata_AUCO$AU_CO <- gsub("United Kingdom", "UK", mydata_AUCO$AU_CO)
mydata_AUCO$AU_CO <- gsub("Russia (Federation)", "Russia", mydata_AUCO$AU_CO)
world <- left_join(world, mydata_AUCO, by = c("region" = "AU_CO"))
ggplot(data = world, aes(x = long, y = lat, group = group, fill = n)) +
theme_void() +
theme(legend.position = "right") +
geom_polygon(color = "white", size = 0.5) +
scale_fill_continuous(high = "dodgerblue4", low = "dodgerblue1")Collaboration des auteurs
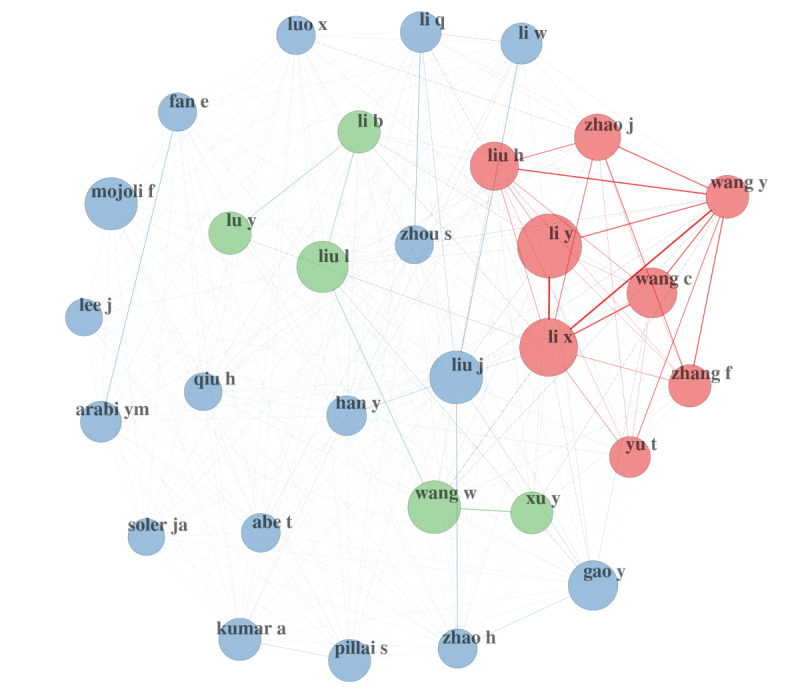
La figure suivante est une illustration des réseaux de collaboration d'auteurs. Bien qu'il s'agisse d'une information à un niveau très élevé, les décideurs politiques ou les agents de santé publique, par exemple, pourraient utiliser ces techniques pour trouver des réseaux plus granulaires, soit juste dans les références du fichier csv, soit en les croisant avec d'autres bases de données. On pourrait même imaginer un croisement avec des données non structurées à des fins spécifiques.
Collaboration des pays
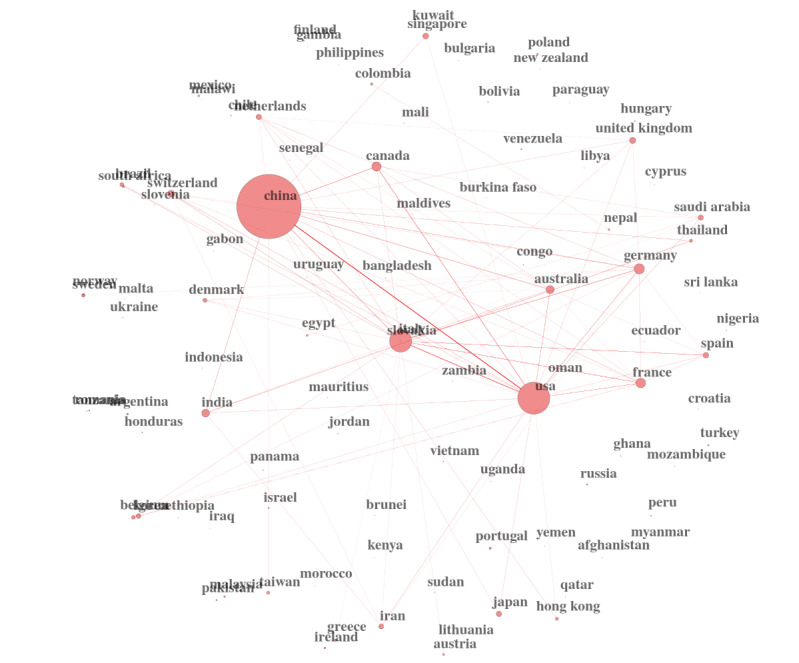
Vous pouvez également utiliser des techniques puissantes telles que la théorie des réseaux sociaux pour trouver des groupes de sujets potentiels, des groupes de chercheurs et des groupes de collaborations nationales. La figure ci-dessous est un exemple de ce dernier. Les États-Unis et la Chine produisent l'essentiel de la recherche sur les coronavirus.
Acknowledgments
To cite this course:
Warin, Thierry. 2020. “Nüance-R: R Courses.” doi:10.6084/m9.figshare.11744013.v2.